Don’t be afraid to break things nature of which you don’t yet understand. As my recent experience shows, the more you break – the more you learn.
Since I started using Linode, I’ve never actually dealt with the Linux much mostly running “apt-get install” or “apt-get upgrade” to make new things available in the environment, and occasionally changing .conf files to tune things up. As setups were getting more complicated (or so I thought by adding more and more to .conf files) a fear of all this being down one day and inability to restore it quickly grew on me.
I mean what if you have nginx/php/MySQL setup on your Linode and as a result of some system issue slice is no longer bootable? What do you do? Who do you run for help to?
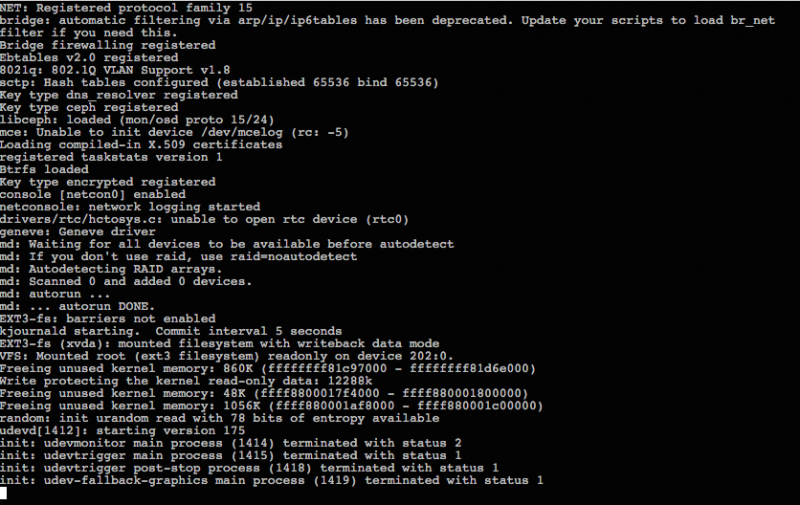
Linode slice stuck at boot
Just like that my client’s Linode slice decided to not boot after an “apt-get upgrade” resulted into broken “udev” package.
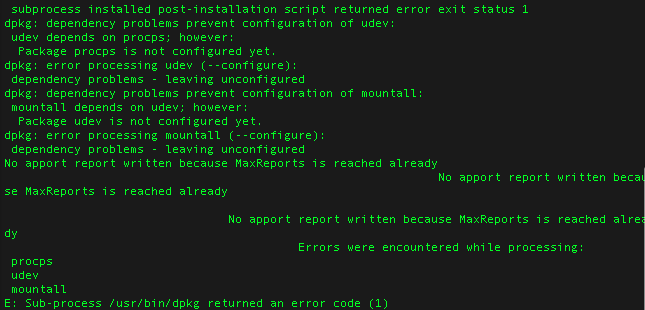
apt-get is not happy
After researching online I have come up with the following plan to fix this situation:
- Turn to Linode’s tech support for help to see, if maybe they will be able to point me in direction of further reading?
- Can they maybe login and configure my slice to boot?
- Text to a Linux guru friend and ask him for help
- Read Linode Rescue mode guide and try to revive slice myself
And here is how it all worked out:
- Linode support responded to my ticket after 26 minutes (!!! – must be because it was Saturday) and was somewhat helpfull further inclining me towards complete redeployment of my slice, stating that by looking into the above boot screen log it is most likely that the system is doomed.
- When I asked them to login and try to fix this for me, they said “Due to liability, we are not able to access your internals.”
- A guru friend was also unavailable right away, later sending text which did not offer much hope: “I am not an expert of ‘udev’…”
- It looks like I was left on my own to fix this following the Rescue Guide…
Rescue or Redeployment sounds scary, because everything needs to be restored to how it was before. But to understand what needs to be done you first need to analyze current setup of your failed deployment.
Let’s look into how we had it before:
- Drupals and WordPresses installed in the LEMP (Linux / nGinx (+ SSL certificates) / mySql / php) environment
- custom Grails application running inside of Tomcat container
And drill down into tasks :
- Drupal:
- we zip and copy websites folder (‘/var/www’)
- nginx configuration files for all the domains this slice hosts (‘/etc/nginx/sites-enabled/’)
- nginx SSL certificates (stores in /etc/ssl/localcerts/)
- mySQL database files : this one was tricky – since ‘mysqld’ wouldn’t run in rescue mode, I wasn’t able to execute database dump, which is the best way to go. So after reading about other means available, I decided to just zip and copy ‘/var/lib/mysql’ folder including all of its contents. It did work out pretty well in the new setup preserving all of my data.
- Grails application saves contents to disk in ‘/srv/www’ subfolders and keeps data in H2 database, which is a file in the app home folder, so:
- we zip application folder which Tomcat deployed it to and that should include code and latest snapshot of the database
- and then we zip and restore ‘/srv/www’ back in place – this is where application data is
Upping new slice and building new setup using one of the StackScripts I put together, was a success. After initial reboot and copying previously downloaded stuff back into places on the new node I was up and running with all the websites serving from this slice just like before. Four hours of stress on otherwise peaceful Saturday were over. Wheeewww…
The above experience got me thinking that maybe I should move all of those into Docker containers, making cases like this less of a problem.
Let me know, if you ended up in the same situation and looking for help – I might be able to answer most of your questions.